Large Language Models (LLMs) can be a big challenge when it comes to computing power and storage needs. It doesn’t matter if you’re running them on your own servers, on the cloud, or on those tiny edge devices—these challenges stick around. One trick to making life easier is by shrinking these models down. This can speed up how quickly they load and make them more responsive. But here’s the tricky part: making them smaller without sacrificing their performance is no walk in the park. There are various techniques for AI model optimization, but each one comes with its own set of compromises between accuracy and speed. It’s a balancing act, but with the right approach, we can unlock the full potential of generative AI and LLMs without breaking a sweat.
Let’s delve into a few optimization techniques:
Distillation
Model distillation involves training a smaller student AI model by harnessing the knowledge of a larger teacher AI model. The student model learns to mimic the behavior of the teacher model, either in the final prediction layer or in its hidden layers. In the first option, the fine-tuned teacher model creates a smaller LLM, which serves as the student model. The teacher model’s weights are frozen and used to generate completions for the training data, while simultaneously generating completions for the student model. The distillation process minimizes the loss function, known as distillation loss, by leveraging the probability distribution over tokens produced by the teacher model’s SoftMax layer. By adding a temperature parameter to the SoftMax function, the distribution becomes broader and less peaked, providing a set of tokens like the ground truth. In parallel, the student model is trained to generate correct predictions based on the training data, using the standard SoftMax function. The difference between the soft predictions from the teacher and the hard predictions from the student forms the student loss. The combined distillation and student losses update the weights of the student model via back-propagation. The main advantage of distillation is that the smaller model can be used for inference in deployment, instead of the teacher model. However, distillation is less effective for generative decoder models and more suited for encoder-only models like BERT, which have significant representation redundancy. It’s important to note that with distillation, you’re training a separate, smaller model for inference without reducing the size of the initial model.
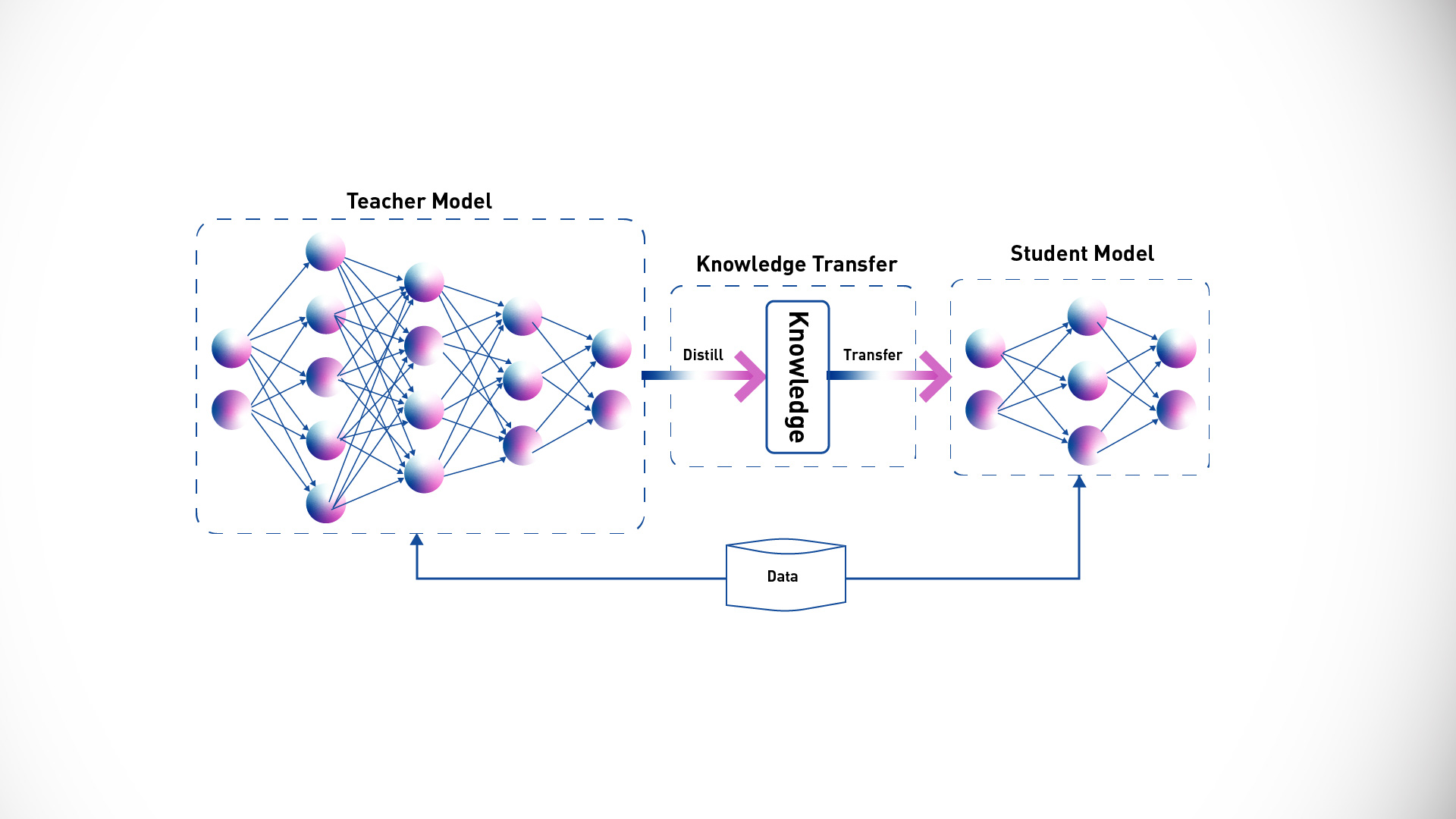
The generic framework for knowledge distillation
Post-Training Quantization
While distillation focuses on knowledge transfer, PTQ is all about downsizing the AI model. (PTQ) is a technique used to reduce the size of a trained model to optimize it for deployment. After a model has been trained, PTQ transforms its weights into lower precision representations, such as 16-bit floating point or 8-bit integers. This reduction in precision significantly reduces the AI model‘s size, memory footprint, and the computer resources needed for serving it.
PTQ can be applied either solely to the model weights or to both the weights and activation layers. When quantizing activation values, an additional calibration step is required to capture the dynamic range of the original parameter values.
Although quantization may lead to a slight reduction in model evaluation metrics, such as accuracy, the benefits in terms of cost savings and performance gains often outweigh this trade-off. Empirical evidence suggests that quantized models, especially those using 16-bit floating points, can maintain performance levels comparable to their higher precision counterparts while significantly reducing model size. Therefore, PTQ is a valuable technique for optimizing models for deployment. Reduce precision of model weights
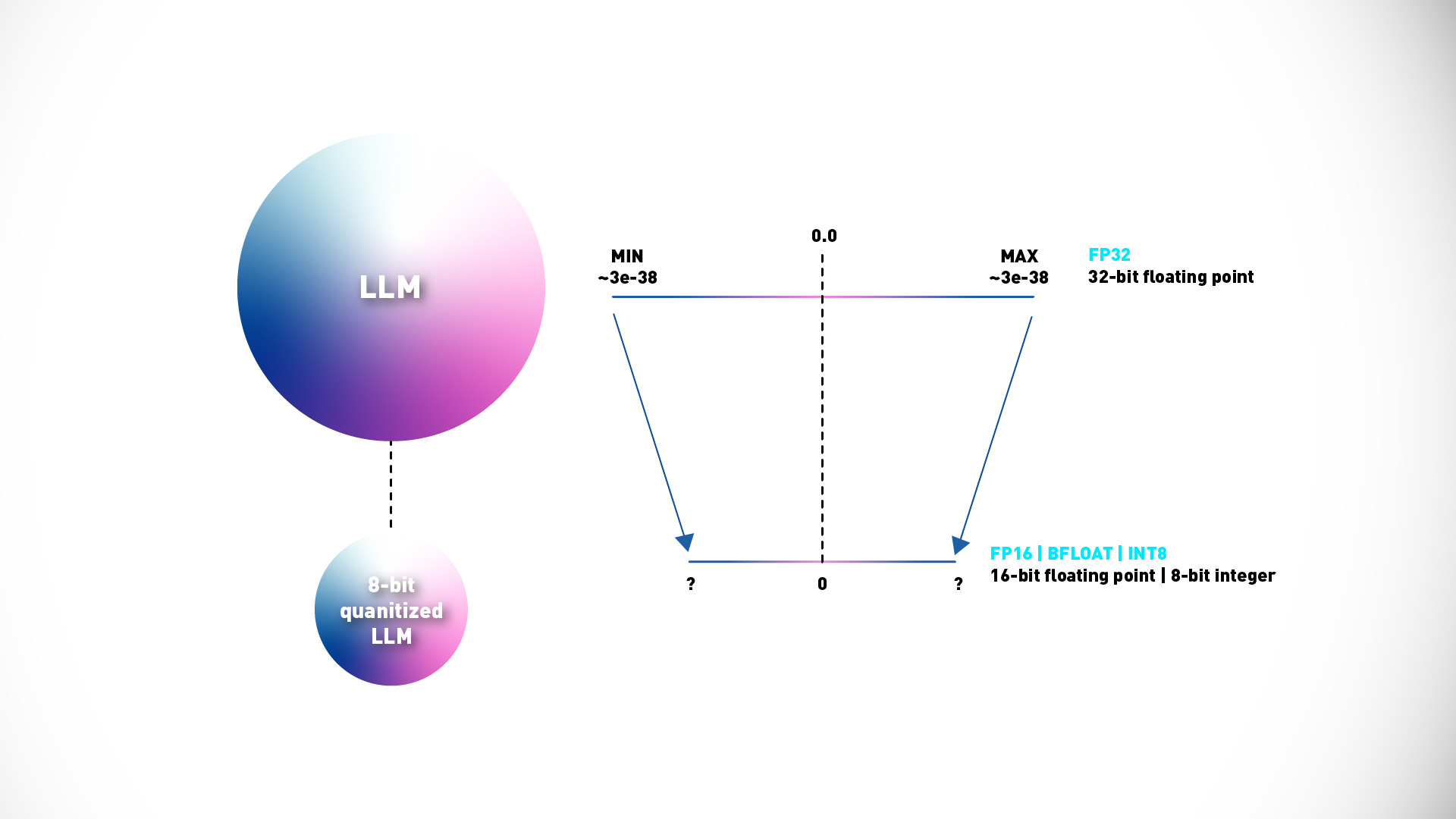
Reduce precision of model weights
Pruning
Pruning is a sophisticated method aimed at trimming down the size of an AI model for inference by removing weights that contribute little to overall performance. These are typically weights with values very close to or equal to zero. Some pruning techniques necessitate full retraining of the model, while others, like LoRA, fall under the umbrella of parameter-efficient fine-tuning.
Moreover, LLM optimization methods focus on post-training pruning, which theoretically reduces the model size and enhances performance. However, in practical scenarios, the impact on size and performance may be minimal if only a small percentage of the model weights approach zero.
When combined with quantization and distillation, pruning forms a powerful trio of techniques aimed at reducing model size without compromising accuracy during inference. Optimizing your AI model for deployment ensures that your application operates smoothly, providing users with an optimal experience. Therefore, integrating these optimization techniques can be crucial for achieving efficient and effective model deployment.
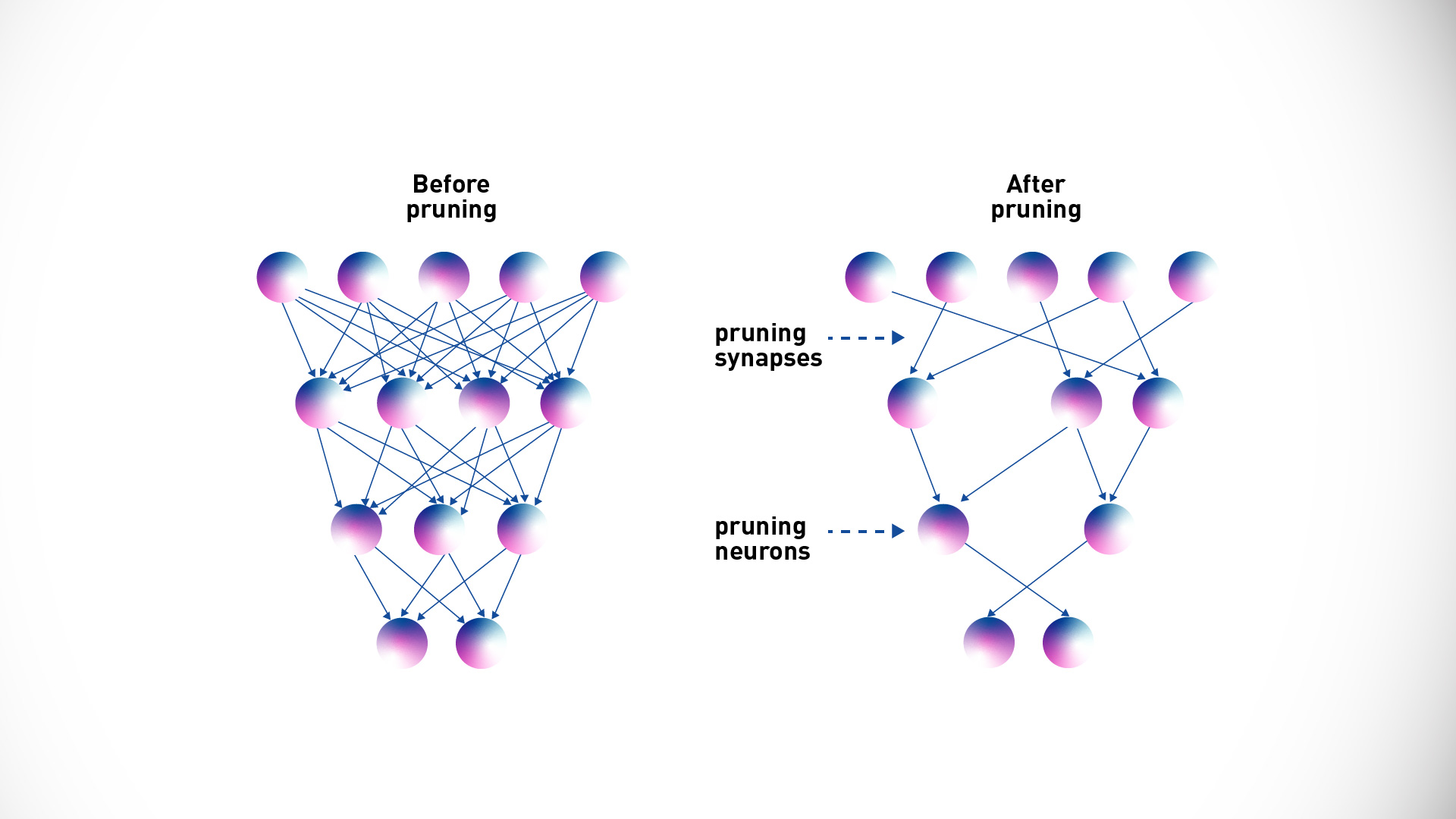
Before and After Pruning of a Neural Network
Conclusion
Optimizing model deployment is essential for efficient utilization of computing resources and ensuring a seamless user experience. Techniques such as distillation, post-training quantization (PTQ), and pruning play pivotal roles in achieving these goals. Distillation offers a method to train smaller models while preserving performance by transferring knowledge from larger teacher models. PTQ further reduces model size by converting weights into lower precision representations, thereby minimizing memory usage and computational resources during inference. Pruning complements these techniques by eliminating redundant parameters, enhancing model efficiency without compromising accuracy. By integrating these optimization methods, we create a robust strategy for model deployment. This integration not only streamlines application operation but also maximizes efficiency across various deployment environments, including cloud, on-premises, and edge devices. Additionally, it enables smoother user experiences by reducing latency and enhancing responsiveness.
To know more about LLMs and generative AI and their application in enterprise automation, write to us at interact@e42.ai or simply click the button below!











